Denoising diffusion probabilistic models
Greetings once again, after a while I am coming back to paper reviews. And what better candidate to select than the buzzing Diffusion models? This variation of the probabilistic generative models was derived from the ideas of nonequilibrium thermodynamics. This will be a series of overviews on the foundations and conceptually important works on the topic of diffusion models from the beginning all the way to modern and well-known Stable Diffusion variants.
TL;DR
Diffusion models are a relatively recent addition to a group of algorithms known as generative models.
The key to the approach is the iterative nature of the diffusion process. Generation begins with random noise but is gradually refined over a number of steps until an output image emerges. At each step, the model estimates how current input can transform into its completely denoised version. Any initial denoising estimation errors that can occur are mitigated by gradual and continual changes at each time step.
The pipeline is as follows:
Feed noisy (at different std schedules) training data into the model ==> evaluate the denoising capabilities ==> adjust model weights ==> iterate until convergence.

Introduction
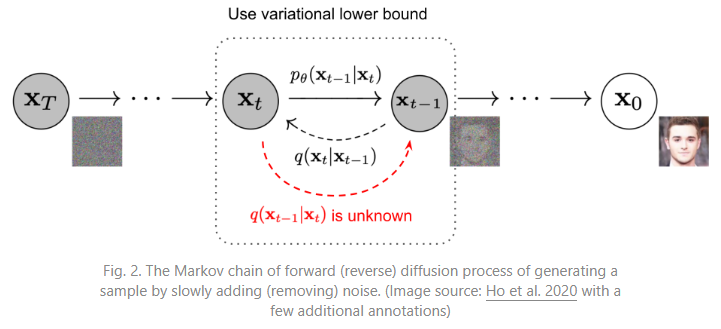
A diffusion probabilistic model is a parameterized Markov chain trained using variational inference to produce samples matching the data after a finite time.
Transitions of this chain are learned to reverse a diffusion process, which is a Markov chain that gradually adds noise to the data in the opposite direction of sampling until the signal is destroyed. When the diffusion consists of small amounts of Gaussian noise, it is sufficient to set the sampling chain transitions to conditional Gaussians too, allowing for a particularly simple neural network parameterization.
Diffusion models are straightforward to define and efficient to train. In addition, a certain parameterization of diffusion models reveals an equivalence with denoising score matching over multiple noise levels during training and with annealed Langevin dynamics during sampling.
Key elements
The forward and the reverse process
Connection with stochastic gradient Langevin dynamics
Langevin dynamics is a concept from physics, defined for modeling molecular systems in a statistical manner. Combined with stochastic gradient descent, stochastic gradient Langevin dynamics can produce samples from a probability density p(x) using only the gradients ∇xlogp(x) in a Markov chain of updates:

Stochastic gradient Langevin dynamics injects Gaussian noise into the parameter updates to hitting local minima, unlike SGD.
KL-divergence for Gaussian comparisons
Diffusion models & denoising autoencoders
Diffusion models might appear to be a restricted class of latent variable models, but they allow a large number of degrees of freedom in implementation. One must choose the variances βt of the forward process and the model architecture and Gaussian distribution parameterization of the reverse process.
Fixing the Beta to constant
Data scaling and reverse process decoder
VAEs and autoregressive models use discretized continuous distributions. Diffusion models similarly maintain the variational bound in a form of a lossless codelength of discrete data.
Simplified training objective
Ho et al. found that training the diffusion model works better with a simplified objective that ignores the weighting term:
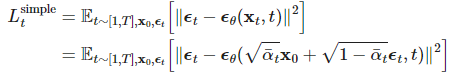
The final simple objective is:
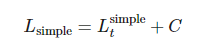
where C is independent of θ constant.
Interpolation
Authors showed that interpolating source images in latent space using q (posterior) as a stochastic encoder, and then decoding the linearly interpolated latent into image space by the reverse process.
Architecture details
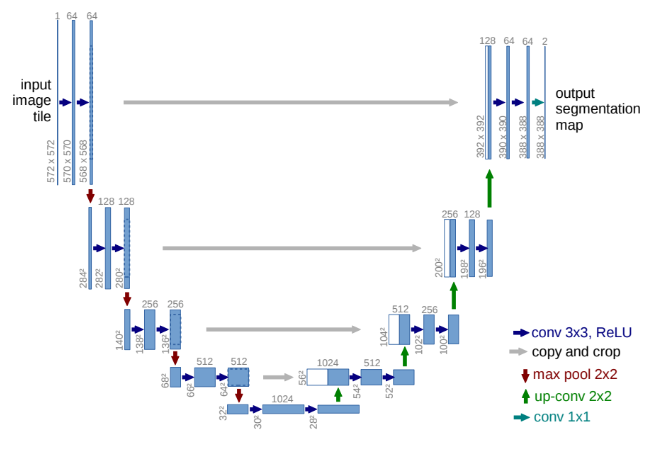
Shortly described, the DDPM is a set of multiple modified PixelCNN++ — U-Nets with skip connections, MHA, and additional time-step embeddings — intertwined with each other via the Markov chain.
Results
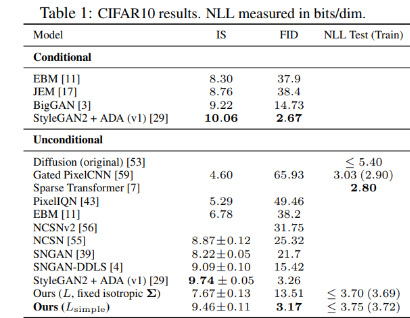
With an FID score of 3.17, the unconditional model achieves better sample quality than most models in the literature of that time. The FID score is computed with respect to the training set, as is standard practice; when calculated with respect to the test set, the score is 5.24, which is still better than many of the training set FID scores in the literature.
Showcase samples
Hope you found the breakdown insightful and relevant. The following chapters are coming soon, have a great rest of your day, and until then!
